Docker 容器化的方式使服务部署维护更加容易,但是 Docker 本身并不能直接调用 GPU cuda 来做一些事情,因此 Nvidia 官方给出了补救方案:Nvidia-Docker。NVIDIA Container Toolkit 允许用户构建和运行 GPU 加速的 Docker 容器。该工具包包括一个容器运行时库和实用程序,用于自动配置容器以利用 NVIDIA GPU。
在线环境安装部署,官方文档安装指引讲的很明白了,按步骤走就行。这里主要讲一下离线部署方式。
环境需求
运行 NVIDIA Container Toolkit 的先决条件列表如下所述:
- 内核版本 > 3.10 的 GNU/Linux x86_64
- Docker >= 19.03(推荐,但某些发行版可能包含旧版本的 Docker。支持的最低版本为 1.12)
- 架构 >= Kepler(或计算能力 3.0)的 NVIDIA GPU
- NVIDIA Linux 驱动程序 >= 418.81.07(请注意,不支持较旧的驱动程序版本或分支。)
Nvidia 驱动程序 .run 下载地址
下载安装包
本文基于 Ubuntu 18.04 LTS x86_64 系统,其他系统下载方式大致相同。
Docker
访问 https://download.docker.com/linux/ubuntu/dists/bionic/pool/stable/amd64/ Ubuntu 18.04 系统 Docker 资源下载页面,其他平台和系统参照官方安装文档操作,或者直接在资源下载页面回退到根目录按自己的平台查找,下载 containerd.io、docker-ce-cli、docker-ce 这三个所需版本的 deb 包,下载命令如下:
wget https://download.docker.com/linux/ubuntu/dists/bionic/pool/stable/amd64/containerd.io_1.5.10-1_amd64.deb
# 或者
curl -OL https://download.docker.com/linux/ubuntu/dists/bionic/pool/stable/amd64/containerd.io_1.5.10-1_amd64.debNVIDIA Container Toolkit
Nvidia-Docker 组件的安装包都对应项目的 Github 存储库的 gh-pages 分支中,自行选择需要的平台和版本:
- nvidia-docker2: https://github.com/NVIDIA/nvidia-docker/tree/gh-pages/
- nvidia-container-toolkit: https://github.com/NVIDIA/nvidia-container-runtime/tree/gh-pages/
- libnvidia-container: https://github.com/NVIDIA/libnvidia-container/tree/gh-pages/
注:Github 下载不能直接使用
wget, 需要替换github.com域名为raw.githubusercontent.com后可用
下面摘录了官方文档的架构和依赖描述,不想了解可以跳到安装部分
架构概述
NVIDIA Container Toolkit 的架构旨在支持生态系统中的任何容器运行时。对于 Docker,NVIDIA Container Toolkit 由以下组件组成(在层次结构中从上到下):
nvidia-docker2nvidia-container-runtimenvidia-container-toolkitlibnvidia-container
下图表示通过各个组件的流程:
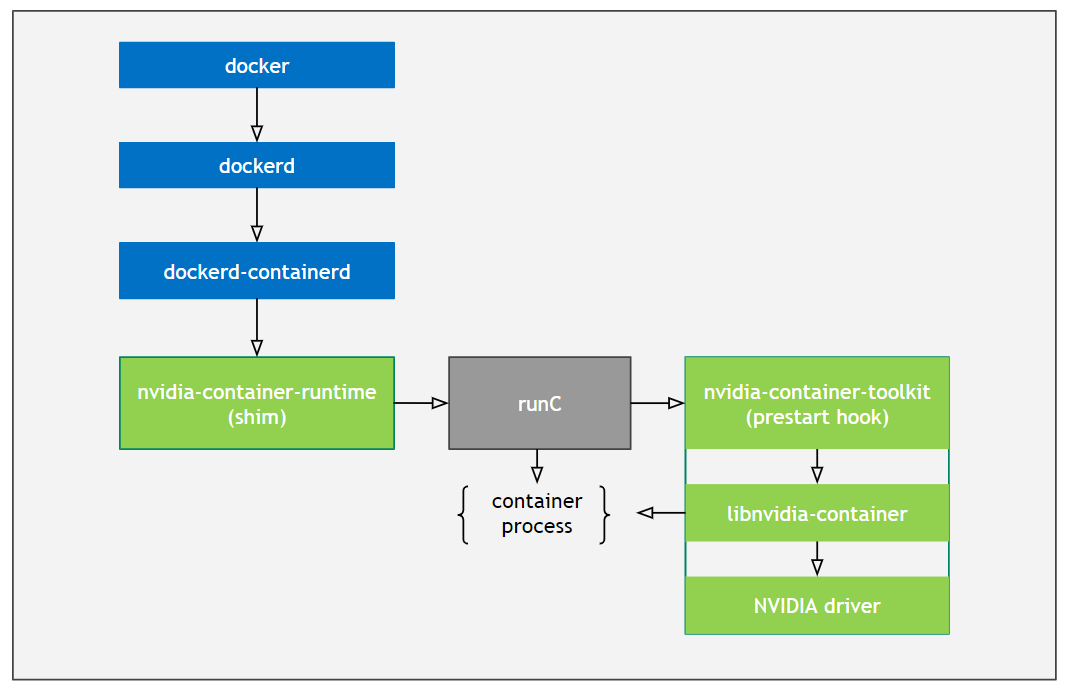
NVIDIA Container Toolkit 的包装也反映了这些依赖关系。如果您从 Docker 的顶级 nvidia-docker2 包开始,则可以看到包依赖项如下:
├─ nvidia-docker2
│ ├─ docker-ce (>= 18.06.0~ce~3-0~ubuntu)
│ ├─ docker-ee (>= 18.06.0~ce~3-0~ubuntu)
│ ├─ docker.io (>= 18.06.0)
│ └─ nvidia-container-runtime (>= 3.3.0)
├─ nvidia-container-runtime
│ └─ nvidia-container-toolkit (<< 2.0.0)
├─ nvidia-container-toolkit
│ └─ libnvidia-container-tools (<< 2.0.0)
├─ libnvidia-container-tools
│ └─ libnvidia-container1 (>= 1.2.0~rc.3)
└─ libnvidia-container1应该使用那个包?
鉴于这种组件层次结构,很容易看出,如果您只安装 nvidia-container-toolkit,那么您将不会安装 nvidia-container-runtime 作为其中的一部分,因此 --runtime=nvidia 将不可用。对于 Docker 19.03+,这很好,因为 Docker 在您传递 --gpus 选项时直接调用 nvidia-container-toolkit,而不是依赖 nvidia-container-runtime 作为代理。
但是,如果您想在 Docker 19.03+ 中使用 Kubernetes,您实际上需要继续使用 nvidia-docker2,因为 Kubernetes 还不支持通过 --gpus 标志将 GPU 信息向下传递给 docker。它仍然依赖 nvidia-container-runtime 通过一组环境变量将 GPU 信息传递到运行时堆栈。
无论使用 nvidia-docker2 还是 nvidia-container-toolkit,都使用相同的容器运行时堆栈。使用 nvidia-docker2 将安装一个瘦运行时,该运行时可以通过环境变量将 GPU 信息代理到 nvidia-container-toolkit,而不是依靠 --gpus 标志让 Docker 直接执行此操作。
为简单起见(和向后兼容),建议继续使用 nvidia-docker2 作为顶级安装包。
安装离线包
检查依赖
安装之前使用 dpkg -I 检查离线包的依赖库是否下载完成,安装顺序也需要按依赖关系进行安装
dpkg -I ./pkg/docker/docker-ce_20.10.9_3-0_ubuntu-bionic_amd64.deb | grep Depends
Depends: containerd.io (>= 1.4.1), docker-ce-cli, iptables, libseccomp2 (>= 2.3.0), libc6 (>= 2.8), libdevmapper1.02.1 (>= 2:1.02.97), libsystemd0可以看到,要安装 docker-ce 20.10.9 版本需要关键依赖 containerd.io 和 docker-ce-cli,其他的均为系统库,且 contain.io 版本必须在 1.4.1 之后才行
安装
使用 dpkg -i 按依赖顺序安装所有离线包,先安装 Docker 环境,再安装 Nvidia-Docker 环境
# Install docker server ...
sudo dpkg -i ./containerd.io_x.y.z-1_amd64.deb
sudo dpkg -i ./docker-ce-cli_x.y.z_3-0_ubuntu-bionic_amd64.deb
sudo dpkg -i ./docker-ce_x.y.z_3-0_ubuntu-bionic_amd64.deb
# Install nvidia-container ...
sudo dpkg -i ./libnvidia-container1_x.y.z-1_amd64.deb
sudo dpkg -i ./libnvidia-container-tools_x.y.z-1_amd64.deb
sudo dpkg -i ./nvidia-container-toolkit_x.y.z-1_amd64.deb
sudo dpkg -i ./nvidia-container-runtime_x.y.z-1_all.deb
sudo dpkg -i ./nvidia-docker2_x.y.z-1_all.deb
# restart docker daemon
sudo systemctl restart docker
# test running
sudo docker run --rm --gpus all nvidia/cuda:11.0-base nvidia-smi注册 runtime
如果已经安装
nvidia-docker2包,请忽略下面内容
安装 nvidia-docker2 包时会配置默认的 runtime 如下:
cat /etc/docker/daemon.json
{
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}如果没有安装 nvidia-docker2 包,需要手动注册 nvidia 运行,请使用以下最适合您的环境的方法。您可能需要将新参数与现有配置合并。提供三个选项:
修改 systemd 文件
sudo mkdir -p /etc/systemd/system/docker.service.d sudo tee /etc/systemd/system/docker.service.d/override.conf <<EOF [Service] ExecStart= ExecStart=/usr/bin/dockerd --host=fd:// --add-runtime=nvidia=/usr/bin/nvidia-container-runtime EOF sudo systemctl daemon-reload \ && sudo systemctl restart docker配置 daemon.json
sudo tee /etc/docker/daemon.json <<EOF { "runtimes": { "nvidia": { "path": "/usr/bin/nvidia-container-runtime", "runtimeArgs": [] } } } EOF sudo pkill -SIGHUP dockerd您可以选择通过将以下内容添加到
/etc/docker/daemon.json来重新配置默认运行时:"default-runtime": "nvidia"命令行
使用 dockerd 添加 nvidia 运行时:
sudo dockerd --add-runtime=nvidia=/usr/bin/nvidia-container-runtime [...]
环境变量(OCI 规范)
用户可以使用环境变量控制 NVIDIA 容器运行时的行为——尤其是枚举 GPU 和驱动程序的功能。每个环境变量都映射到来自 libnvidia-container 的 nvidia-container-cli 的命令行参数。这些变量已经在 NVIDIA 提供的基本 CUDA 镜像中设置。
GPU 枚举
从 Docker 19.03 开始,可以使用 --gpus 选项或环境变量 NVIDIA_VISIBLE_DEVICES 将 GPU 指定给 Docker CLI。此变量控制容器内可以访问哪些 GPU。
NVIDIA_VISIBLE_DEVICES 变量的值可能为:
| 可能的值 | 描述 |
|---|---|
0,1,2, 或 GPU-fef8089b |
GPU UUID 或索引的逗号分隔列表 |
all |
所有 GPU 都可以访问,这是基本 CUDA 容器映像中的默认值 |
none |
将无法访问任何 GPU,但将启用驱动程序功能 |
void 或 不设置 |
nvidia-container-runtime 将具有与 runc 相同的行为(即既不公开 GPU 也不公开功能) |
使用
NVIDIA_VISIBLE_DEVICES变量时,您可能需要将--runtime设置为nvidia,除非已设置为默认值。
举一些栗子
# 启动启用 GPU 的 CUDA 容器
docker run --rm --gpus all nvidia/cuda nvidia-smi
docker run --rm --runtime=nvidia \
-e NVIDIA_VISIBLE_DEVICES=all nvidia/cuda nvidia-smi
# 启动 GPU 的容器使用特定 GPU
docker run --gpus '"device=1,2"' \
nvidia/cuda nvidia-smi --query-gpu=uuid --format=csv
docker run --gpus device=GPU-18a3e86f-4c0e-cd9f-59c3-55488c4b0c24 \
nvidia/cuda nvidia-smi驱动功能
NVIDIA_DRIVER_CAPABILITIES 控制哪些驱动程序库/二进制文件将安装在容器内。
NVIDIA_DRIVER_CAPABILITIES 变量的值可能为:
| 可能的值 | 描述 |
|---|---|
compute,video 或 graphics,utility |
容器需要的驱动程序功能的逗号分隔列表 |
all |
启用所有可用的驱动程序功能 |
| 空 或 不设置 | 使用默认驱动程序功能:实用程序、计算 |
支持的驱动程序功能如下表所示:
| 驱动功能 | 描述 |
|---|---|
compute |
CUDA 和 OpenCL 应用程序需要 |
compat32 |
运行 32 位应用程序所必需的 |
graphics |
运行 OpenGL 和 Vulkan 应用程序 |
utility |
使用 nvidia-smi 和 NVML 所需的 |
video |
需要使用视频编解码器 SDK |
display |
利用 X11 显示所需的 |
例如,指定 compute 和 utility 功能,允许使用 CUDA 和 NVML
docker run --rm --runtime=nvidia \
-e NVIDIA_VISIBLE_DEVICES=2,3 \
-e NVIDIA_DRIVER_CAPABILITIES=compute,utility \
nvidia/cuda nvidia-smi
docker run --rm --gpus 'all,"capabilities=compute,utility"' \
nvidia/cuda:11.0-base nvidia-smi约束
NVIDIA 运行时还提供了对容器支持的配置定义约束的能力。
NVIDIA_REQUIRE_*,该变量是一个逻辑表达式,用于定义容器上的软件版本或 GPU 架构的约束。
下面提供了支持的约束:
| 约束 | 描述 |
|---|---|
cuda |
对 CUDA 驱动程序版本的约束 |
driver |
对驱动程序版本的限制 |
arch |
对所选 GPU 的计算架构的约束 |
brand |
对所选 GPU 品牌的限制(例如 GeForce、Tesla、GRID) |
多个约束可以在单个环境变量中表示:空格分隔的约束是 逻辑或关系,逗号分隔的约束是 逻辑与关系, NVIDIA_REQUIRE_* 形式的多个环境变量是 逻辑与 在一起的。
例如,可以为容器映像指定以下约束,以约束支持的 CUDA 和驱动程序版本:
NVIDIA_REQUIRE_CUDA "cuda>=11.0 driver>=450"Dockerfiles 配置
可以通过环境变量在镜像中设置功能和 GPU 枚举。如果在 Dockerfile 中设置了环境变量,则不需要在 docker run 命令行中设置它们。
例如,如果您正在创建自己的自定义 CUDA 容器,可以设置环境变量的默认值如下:
ENV NVIDIA_VISIBLE_DEVICES all
ENV NVIDIA_DRIVER_CAPABILITIES compute,utility这些环境变量已经在 NVIDIA 提供的 CUDA 镜像中设置。
